データベースシステムは、データベースに蓄積したデータを再利用するためのソフトウェアです。
桐にも、条件に適合するデータを集める(「絞り込み」)、探す(「検索」)、
並べ替える(「並べ替え」)などのデータ操作が豊富に揃っていますが、ポイントはその考え方です。
桐では条件に適合したデータの集合に対して、さらにデータ操作を実行することができます。
それってどういう事?
例えばこういうストーリーを考えてみましょう。
①名簿から20歳以上の人を集めて→②データを眺めてみたら地域に偏りがある事が判ったので特定の地域の人に絞り込んで→
③さらにどうやら60歳以上の人のデータは不要なので60歳以上の人のデータを除外して→④そのデータを性別・職業別に分類して集計表を出力する。
4つのステップでデータベースを分析するストーリーです。
桐なら、そのストーリーの通りにデータの再利用ができます。それは桐の機能が、そのときのデータの集合に対して作用するように設計されているからです。
対して一般のデータベースならどうでしょう?②をやろうとしたときには①と②のクエリーを組合せて、③が必要だと判ったときには①と②と③の組合せのクエリーを作り直して、
最後の④にたどり着いたときに①~④までの条件を反映したクエリーをまとめ上げて...気が遠くなりませんか?
思考の流れに沿ったデータベースであるための重要なポイントが、「条件に適合したデータの集合に対して、さらにデータ操作を実行する」ということです。桐のすべての機能はこの考え方で統一されています。
データベースから必要なデータだけを集めてくる操作が絞り込みです。 桐のデータ操作の機能は、ここで作られたデータの集合が対象になります。 もちろん絞り込みの結果に対して、さらに絞り込みを行うこともできます。 つまり複雑な条件を一気につくらなくても、判ることから順番に絞り込みをしていけば必要なデータが集められます。
絞り込みには値を指定し比較方法を選ぶだけの「絞り込み:値」、桐の豊富な関数を利用していろいろな条件に合ったレコードを選ぶ
「絞り込み:比較式」、また複数の項目の条件を指定し、より高度な抽出を行う「絞り込み:条件」があります。
"拡張辞書順" 検索を使用すると、全角と半角、ひらがなとカタカナ、清音・濁音・半濁音、繰り返し文字(々, ヽ, ゝ等)を同一文字とみなした日本語向けの絞り込みが行えます。
![[絞り込み:値]画面](img/menu3-2-1.png)
そのほかにも、画面上で絞り込む行を任意に指定できる「絞り込み:選択行」や、同じ値を単一化して抽出する「絞り込み:単一化」、 重複をチェックする「絞り込み:重複行」など実用に便利な機能が用意されています。
![[絞り込み:重複行]画面](img/menu3-2-2.png)
絞り込みには紹介しなければならない特長があと2つあります。1つは、前の絞り込みに戻すことができることです(絞り込みを何回繰り返していても、最初の状態に1つずつ戻していくことができます)。
行きつ戻りつしながらデータを集める条件を検討する、人間の思考に沿った機能になっています。
最後の特長は、現在の絞り込み状態と直前の状態の差分をとる「絞り込み:補集合」が用意されていることです。
『あ、そうじゃなくて、その逆!!』そんな指示に応えられるデータベースシステムは桐だけです。
必要なデータが集まったら、次は並び順の調整です。並べ替えは現在のデータの集まりの並び順を一時的に変更する機能です。
50個までの並べ替え条件が定義できるので、用途に合わせて必要な並び順に切り替えられます。
もちろん索引を定義しておけば、並べ替えの時間もあっという間です。
並べ替えのルールに辞書順を指定すると、「あ、ア、い、イ、…」など、ひらがなの次に同じ音のカタカナのデータが並ぶ、正確な五十音順の並べ替えが可能です。
現在のデータの集まりの中から特定の行(レコード)を探すときに使う機能が検索です。
指定の方法は絞り込みと同じ、値、比較式、条件の3通り。
検索対象の項目をあらかじめ索引として定義しておけば、自動的に索引が利用されて検索が高速化されます。
一括してデータの書き換えを行うための機能が置換です。絞り込みと組み合わせることで、データベース中の必要なデータだけを一括変更できます。
全角で入力した番号を半角に変換する、商品価格を一律5%OFFにする等、一度にデータを変更したいときに使います。
複数項目間の連結や計算、多種の文字列操作関数を使用しての文字列変換、表(データベース)に登録されている計算式の再計算など、単なる値の変更にとどまらないさまざまな一括変更ができます。
選んだ項目について、条件や計算式の設定なしにワンタッチで集計をする機能が項目集計です。
現在のデータの集まりの中の指定項目について、レコード件数、入力済みレコード件数、削除レコード件数、最大値、最小値、合計値、平均値や標準偏差を集計します。
![[項目集計]画面](img/menu3-6.png)
任意の計算式でデータの集まりを集計する機能が行集計です。
日時・月・商品・得意先・学年・クラスなど集計用のグループを設定する機能が含まれているので、ワーク表を作ったり、集計用にデータの順番制御をしたり等の面倒な前処理は一切不要です。
この行集計機能と、一覧表印刷機能を組み合わせるだけで、大抵の管理帳票が作れてしまいます。
たとえば、売上一覧から、[売上日]を縦に、[支店名]を横に展開して、売上日別支店ごとの集計表を作成したいときがあります。そのような時に使う機能が転置集計です。
ふたつの項目を縦と横のグループとして展開し、交わる部分を集計します。
ふたつの表(データベース)のデータを照合し、処理を行う機能が併合です。
一致した場合にデータを置きかえる「置換」、一致するデータがなかった場合に新しいレコードを作る「挿入」、一致するデータを削除する「削除」、
一致するデータのみを表示する「絞り込み」、「置換」と「挿入」の処理を同時に行う「置換挿入」、突き合わせた項目の「連結」や「加減算」が組み込みの
処理として用意されているので、プログラムやクエリーの準備をしなくても簡単に在庫更新やマスタファイルの更新などの実務が行えます。
![[併合条件]画面](img/menu3-10.png)
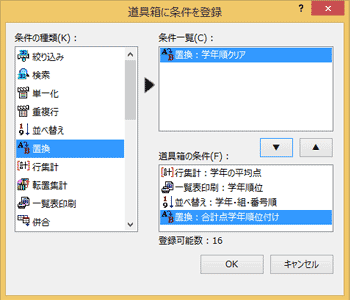
桐のデータ処理機能は「条件」という形で保存して、再実行が簡単になるようにしています。この「条件」を使いやすい場所に並べておくための機能が道具箱です。
よく使う「条件」を道具箱に登録しておくと、メニューなどの操作なしに実行できます。
例えば特定の条件で絞り込んで、それを集計するという操作が定型化されているなら、それぞれの「条件」を道具箱に登録するのがおすすめです。
アイコンを2回クリックするだけで集計までをすませる事ができます。

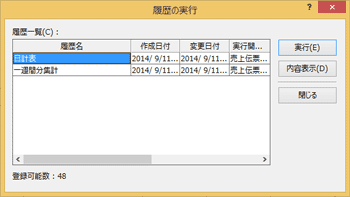
一度行った一連の処理を再実行するための機能が履歴です。実行した作業の手順を記憶し、あとで再生することができます。
例えば、販売表で本日分のレコードを「絞り込み→行集計を実行→一覧表印刷→絞り込み解除」の処理を記録しておけば、履歴実行の操作だけで、日計表の印刷が行えます。
大事なポイントは、この履歴の内容は一括処理のプログラムコードそのものであることです。
手作業で行っている操作をシステム化するときにも、履歴は大きな力を発揮します。